简介
文章首次提出将生成对抗网络(Generative Adversarial Network, GAN)用于解决超分辨率(Super Resolution, SR)问题。文章提到将均方差作为内容损失(Content Loss)虽然能够获得较高的峰值信噪比(PSNR),但同时也会导致缺失高频细节。由此,作者提出采用感知损失(Perceptual Loss)和对抗损失(Adversatial Loss)使得生成的图片和目标图片在语义和风格上更相似,虽然PSNR值并没有经过Bicubic或SRResNet生成的图片高,但是提高了生成图片的视觉感受。
模型
SRGAN的网络结构如下图所示:
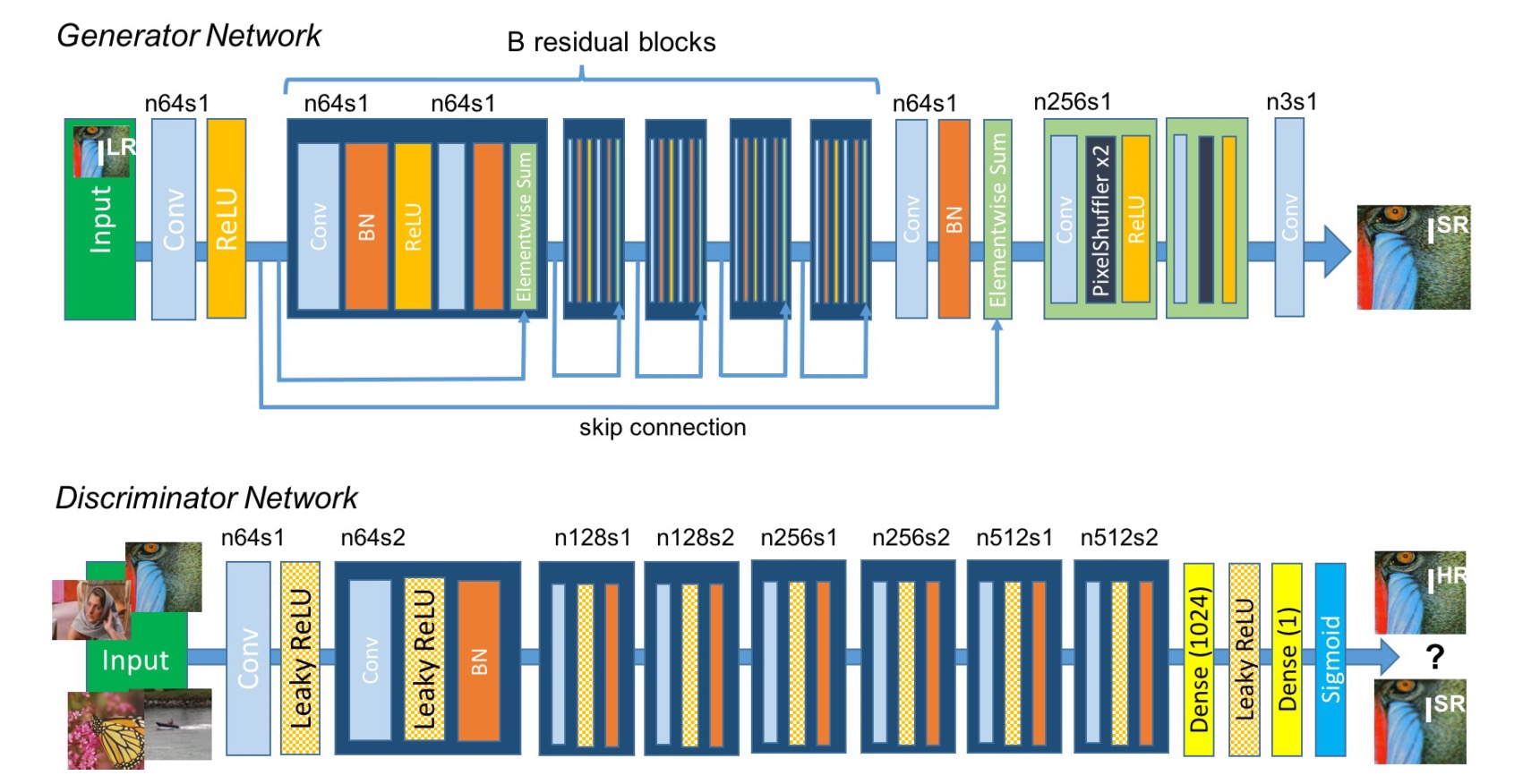
在生成网络部分(SRResNet)部分包含多个残差块,每个残差块中包含两个3×3的卷积层,卷积层后接批规范化层(batch normalization, BN)和PReLU作为激活函数,两个2×亚像素卷积层(sub-pixel convolution layers)被用来增大特征尺寸。在判别网络部分包含8个卷积层,随着网络层数加深,特征个数不断增加,特征尺寸不断减小,选取激活函数为LeakyReLU,最终通过两个全连接层和最终的sigmoid激活函数得到预测为自然图像的概率。
结论
文章中的实验结果表明,用基于均方误差的损失函数训练的SRResNet,得到了结果具有很高的峰值信噪比,但是会丢失一些高频部分细节,图像比较平滑。而SRGAN得到的结果则有更好的视觉效果。其中,又对内容损失分别设置成基于均方误差、基于VGG模型低层特征和基于VGG模型高层特征三种情况作了比较,在基于均方误差的时候表现最差,基于VGG模型高层特征比基于VGG模型低层特征的内容损失能生成更好的纹理细节。